-
[Redis] Redis에 대해서 (Redis란, 특징, 영속성, 자료구조, 아키텍처)Computer Science/Database 2023. 12. 10. 20:15728x90
데이터와 트랙픽의 양이 기하급수적으로 증가하면서 한대의 관계형 데이터베이스를 사용하는 것은 큰 비용이 든다. 이런 상황에서 NoSQL은 여러 대의 컴퓨터에 데이터를 분산하여 저장하는 것을 목표로 등장했다.
NoSQL 데이터베이스 중 하나인 Redis는 key-value 형태로 저장하는 인메모리 데이터 베이스로서 데이터베이스 뿐만 아니라 캐시, 메시지 브로커 및 스트리밍 엔진 등 다양한 용도로 사용되는 오픈소스이다.
Redis에 대해서 자세히 알아보자!
📍 Redis란?
Redis는 Remote Dictionary Server의 약자로 외부 딕셔너리(key-value) 형태의 서버이다. NoSQL 데이터베이스 중 하나로 고급 키-값 저장소이다.
In-Memory 데이터 베이스로서 memcached와 유사한 캐시 시스템이기도 하다. (memcached와의 차이점은 뒤에서 설명)
원자적 연산을 실행할 수 있으며 트랜잭션, on-disk persistence(디스크 영속성), Redis Sentinel 및 Redis Cluster를 통한 자동 파티셔닝과 같은 유용한 기능을 제공한다.
데이터베이스 뿐만 아니라 캐시, 메시지 브로커 및 스트리밍 엔진 등 다양한 용도로 사용할 수 있다.
In-Memory 데이터 베이스
in-memory 데이터베이스는 disk-based 데이터베이스와 달리 말그대로 메모리에 데이터를 저장하는 데이터베이스이다.
메모리에 데이터를 저장하는 것은 어떤 특징을 가지고 있을까?
1. disk-based 데이터베이스보다 빠른 속도
in-memory DB는 메모리에 데이터를 저장하고 직접 처리하기 때문에 빠른 응답시간을 제공한다.
그럼 disk-based DB는 왜 느릴까?
디스크와 같은 외부 저장 장치에 데이터를 저장하여 데이터를 읽을 때 바로 해당 데이터를 사용할 수 없다. 외부 저장 장치에서 데이터를 읽으면 이를 메모리에 올리고 메모리에서 데이터를 읽어와야 하기 때문이다. 메모리에서 바로 데이터를 읽을 수 있는 in-memory 방식에 비해 느릴 수 밖에 없다.
2. ORM 과정 불필요
메모리에 데이터를 저장할 경우 객체, 리스트 형태의 다양한 구조의 데이터를 저장할 수 있다. 하지만 RDBMS의 경우 행열 구조의 2차원 테이블 형태로 데이터를 저장하기 때문에 우리가 사용하는 객체와 RDBMS 테이블 간의 변환이 필요하다. 일이렇게 RDBMS는 ORM 과정이 필요한 반면 인메모리 방식은 메모리에 바로 저장하기 때문에 ORM 과정이 필요하지 않다.
3. 메모리 휘발성
메모리에 저장된 데이터는 전원이 꺼지면 데이터가 손실 된다. 이를 휘발성이라고 하는데 인메모리 데이터베이스의 경우 휘발성을 가진다. 반대로 disk에 데이터를 저장하는 disk-based 데이터베이스의 경우 데이터의 영속성을 가진다.
4. 저장 공간 제약
컴퓨터 메모리인 RAM의 경우 용량이 정해져있다. 따라서 인메모리 데이터베이스의 경우 메모리에 데이터를 저장하기 때문에 저장 공간의 제약이 존재한다.
✨ Redis 특징
Redis의 특징으로는 다음을 들 수 있다.
- 영속성을 지원하는 인메모리 데이터 저장소
- 다양한 자료구조
- 읽기 성능 증대를 위한 서버 측 복제를 지원
- 쓰기 성능 증대를 위한 클라이언트 측 샤딩 지원
- 원자적 작업 실행
- 트랜잭션
▷ 영속성을 지원하는 인메모리 데이터 저장소
Redis는 인메모리 데이터베이스의 단점인 메모리 휘발성을 극복하기 위해 영속성을 지원한다. 데이터를 디스크에 저장하여(on-disk persistence) 서버 재시작 시 데이터 보존한다. 메모리에 데이터를 저장하고 나면 백그라운드로 디스크에도 저장하는데 저장 방식에는 스냅샷 방식과 로그 방식이 있다.
- 스냅샷 방식
- 주기적으로 데이터베이스 스냅샷을 디스크에 저장
- 스냅샷은 특정 시점의 데이터 상태를 정적으로 저장하는 방식
- 로그 기반 방식
- 변경된 데이터를 지속적으로 로그에 기록
- 시스템 장애시에도 로그를 통해 데이터를 복구하는 방식
데이터베이스 상태를 지속적으로 디스크에 저장하여 장애 발생 시에도 복구 가능한 데이터를 확보할 수 있다. 즉 백업 및 복원 가능!
redis에서는 두 가지 저장 방식에 대해 영속성 방식을 설정할 수 있도록 지원한다.
▷ 다양한 자료구조
문자열, 리스트, 해시, 셋, 정렬된 셋과 같은 다양한 데이터형, 컬렉션을 지원한다.
▷ 읽기 성능 증대를 위한 서버 측 복제를 지원
Redis에선 Replication 구성(master-replica 노드 구성)을 통해 서버를 복제할 수 있다. replica(복제된 노드)는 데이터를 복제하여 동일한 데이터를 유지한다. 주 서버(master)에서 쓰기 요청을 담당하고, 여러 replica에서 읽기 요청을 병렬적으로 처리하여 읽기 요청 여러 노드에 분산하여 전체 시스템의 읽기 처리량을 향상시킨다. 또한 주 서버(master) 장애 시에도 replica를 통해 계속해서 읽기 요청을 처리 할 수 있어 고가용성을 제공한다.
▷ 쓰기 성능 증대를 위한 클라이언트 측 샤딩 지원
샤딩(sharding)은 데이터를 분산해서 저장하고 처리하는 데이터베이스 설계이다. Redis Cluster를 사용하게 되면 샤딩(sharding)을 통해 여러 master 노드에 데이터를 분산 저장하고 처리하기 때문에, 쓰기 작업을 병렬로 분산시켜 쓰기 성능이 향상된다.
▷ 원자적 작업 실행
Redis는 Single Thread를 통해 race condition을 방지하기 때문에 원자적 작업이 가능하다. [Redis 단일 스레드 특성]
▷ 트랜잭션
Redis는 명령들에 대해 싱글스레드로 처리하여 원자성을 보장한다.
그렇다면 어떻게 많은 사용자들이 빠른 속도로 redis를 사용할 수 있을까? [참고]
Redis는 병렬성은 없지만 동시성이 있어, 동시성 문제가 생길 수 있다.
- 병렬성 : 두 가지 이상의 작업이 동시에 진행되는 것 ex) 두 직원이 각각 손님을 응대
- 동시성 : 두 가지 이상의 작업이나 요청이 시간 순서에 따라 진행되는 것 ex) 한 직원이 두 명의 손님을 동시에 응대
Redis Transaction을 보면 트랜잭션을 위한 MULTI, EXEC, DISCARD, WATCH 명령어를 제공한다. 이 중 WATCH 명령을 사용하면 Optimistic Locking(낙관적락)으로 동시성 문제를 해결할 수 있다.
추가적으로 RDB와 다른 점은 Rollback을 지원하지 않는다. 그렇기 때문에 중간에 실패하더라도 실패한 명령을 제외하고 나머지 명령들은 모두 실행하는 특징이 있다.
⌛ Redis의 영속성
Redis는 인메모리 데이터베이스로 데이터의 휘발성을 가지지만, 이를 해결하기 위해 영속성을 제공한다. 원하는 영속성 방법을 설정하여 디스크에 데이터를 저장함으로써 백업 및 복구를 위한 데이터를 확보할 수 있다.
Redis persistence
How Redis writes data to disk
redis.io
RDB(Redis Database)
- 지정된 간격으로 데이터 세트의 특정 지점 스냅샷을 수행
- 백업에 적합
- redis가 작동을 멈추는 경우 최신 데이터를 손실할 수 있음
AOF(Append Only File)
- 서버에서 수신한 모든 쓰기 작업을 로그로 기록
- 쓰기 작업이란 데이터베이스에 변경을 가하는 모든 명령(데이터 추가, 수정, 삭제)
- 데이터 손실없이 안전하기 때문에 내구성 있음
- 동일한 데이터 세트에 대해 RDB 파일보다 큼
RDB+AOF
- 지정된 간격으로 스냅샷을 수행하고 간격 사이의 쓰기작업에 대해 로그로 기록
🔎 Redis 자료구조

출처 : [NHN FORWARD] Redis 야무지게 사용하기, Redis 운영팁 ▷ String
- 문자열 데이터를 저장 및 조회할 수 있는 기본 자료
- 문자열은 텍스트, 직렬화된 객체, 바이너리 배열을 포함한 바이트 시퀀스를 권장
- 캐싱에 자주 사용되지만 카운터를 구현하고, 비트 단위 연산을 수행할 수 있는 기능도 지원
- HTML fragment나 페이지 캐싱에 사용
- 문자열에 이진데이터가 포함될 수 있어 JPEG 이미지를 저장 가능
- redis의 문자열은 최대 512MB까지만 가능하다.
함수명 명령어 설명 GET GET key 문자열 값 검색 SET SET key value 키가 존재하는 경우 기존 값을 대체하고, 아닌 경우 새로 할당 MGET MGET key [key ...] 지정된 모든 key의 value를 배열로 반환 (존재하지 않는 키는 특수값 nil 반환) MSET MSET key value [key value ....] 여러 key에 대해 value로 설정 INCR INCR key key에 저장된 value를 1씩 증가 (키가 없으면 디폴트 0으로 설정) INCRBY INCRBY key increment key에 저장된 value를 increment만큼 증가 (키가 없으면 디폴트 0으로 설정) INCRBYFLOAT INCRBYFLOAT key increment key에 저장된 부동 소수점 숫자를 나타내는 value를 increment만큼 증가 DECR DECR key key에 저장된 value를 1씩 감소 (키가 없으면 디폴트 0으로 설정) DECRBY DECRBY key decrement key에 저장된 value를 decrement만큼 감소 (키가 없으면 디폴트 0으로 설정) GETRANGE GETRANGE key start end key에 저장된 value에 대해 start부터 end 전까지 반환 SETRANGE SETRANGE key offset value key에 저장된 value에 대해 offset부터 value로 덮어씀 ▷ Bitmap
- 실제 데이터 유형이 아닌 비트 연산을 사용할 수 있는 자료 구조
- 비트 벡터처럼 처리되는 String 유형에 정의
- String의 최대 길이는 512MB로 2^32개이 서로 다른 비트를 설정 가능
함수명 명령어 설명 SETBIT SETBIT key offset value key에 저장된 문자열 값의 offset에서 비트를 설정하거나 지움 GETBIT GETBIT key offset key에 저장된 문자열 값의 offset에 있는 비트 값을 반환 BITOP BITOP <AND|OR|XOR|NOT> destkey key [key ...] 여러 key간에 비트 단위 연산을 수행하고 결과를 destkey에 저장 BITCOUNT BITCOUNT key [start end [BYTE | BIT]] 문자열에서 설정된 비트 수를 계산 BITPOS BITPOS key bit [start [end [BYTE | BIT]]] 문자열에서 1 또는 0으로 설정된 첫 번째 비트의 위치를 반환 ▷ List
- 문자열 값이 연결된 리스트 데이터
- 스택과 큐를 구현하고, 백그라운드 작업자 시스템을 위한 대기열 관리를 구축
- 링크드 리스트(Linked List) 형태로 서로 연결되어 있음
- 데이터를 head와 tail에 삽입 삭제 가능, 중간 값 삭제 시 인덱스를 찾고 해당 인덱스를 제거하는 함수 사용
- blocking 기능을 제공하여 작업 큐에서 사용 가능
- producer/consumer에서 큐가 비었을 때 소비자가 POP을 시도하면 NULL을 반환한다.
- 이 경우 소비자는 기다렸다가 잠시후 다시 시도해야한다. (Polling)
- BRPOP, BLPOP을 사용하면 목록이 비었을 때 차단하고 목록에 추가되거나 제한시간에 도달했을 때 반환한다.
함수명 명령어 설명 LPUSH LPUSH key element [element ...] 지정된 모든 element를 key에 저장된 리스트의 head에 삽입 RPUSH RPUSH key element [element ...] 지정된 모든 element를 key에 저장된 리스트의 tail에 삽입 LPOP LPOP key [count] key에 저장된 리스트의 첫번째 요소를 제거하고 반환 RPOP RPOP key [count] key에 저장된 리스트의 마지막 요소를 제거하고 반환 LLEN LLEN key key에 저장된 리스트의 길이 반환 LMOVE LMOVE source destination <LEFT|RIGHT> <LEFT|RIGHT> source에 저장된 리스트의 첫번째|마지막 요소를 destination에 저장된 리스트의 첫번째|마지막 요소로 이동 LTRIM LTRIM key start stop key에 저장된 리스트의 start부터 stop까지 포함하도록 자름 BLPOP BLPOP key [key ...] timeout key에 저장된 리스트의 head에서 요소를 제거하고 반환
목록이 비었으면 요소를 사용할 수 있거나, 제한시간까지 명령 차단BRPOP BRPOP key [key ...] timeout key에 저장된 리스트의 tail에서 요소를 제거하고 반환
목록이 비었으면 요소를 사용할 수 있거나, 제한시간까지 명령 차단BLMOVE BLMOVE source destination <LEFT|RIGHT> <LEFT|RIGHT> source 리스트의 요소를 destination 리스트로 이동
source가 비었으면 새 요소를 사용할 수 있을 때까지 명령 차단▷ Hashe
- 필드(field)와 밸류(value)로 구성된 해시 자료구조
- 객체를 나타내고 카운터 그룹을 저장할 수 있음
- 해시 데이터는 레디스 키와 매핑되어 있으므로 해시 value를 생성 및 조회 하려면 레디스 키와 필드를 동시에 사용해야함
▷ Set
- 문자열이 순서가 지정되지 않은 집합 데이터
- 중복을 허용하지 않는 자료구조
- 교집합, 합집합, 차집합 등 일반적인 집합 연산 수행 가능
- 고유 항목 추적(특정 블로그 게시물에 액세스하는 모든 IP 추적)이나 관계(주어진 역할을 가진 모든 사용자 집합)을 나타낼 때 사용됨
▷ Sorted Set
- Set과 비슷한 집합 데이터
- 스코어 값을 사용하여 정렬하고 스코어 값이 중복되면 사전 순으로 정렬
- 리더보드(게임 점수 순위)에서 사용
▷ Hypperloglog
- 집합의 카디널리티(데이터) 개수를 추정할 수 있는 확률적 데이터 구조(0.81% 표준 오차)
- 최대 12KB를 사용할 수 있음
- 기간, 페이지 별로 Hypperloglog를 생성하여, 방문할 때마다 모든 IP/식별자를 추가함으로써 웹페이지 익명 고유 방문(SaaS, 분석도구)에 활용
- 웹 사이트 방문 ip 개수 카운팅, 하루 종일 크롤링 한 url 개수 몇개 인지, 검색 엔진에서 검색 한 단어 몇개 인지 -> 엄청 크고 유니크 한 값 카운팅 할 때 활용
▷ Stream
- 로그의 append-only만 가능한 자료구조
- 이벤트성 로그를 처리할 수 있음
- 일종의 메세지 서비스 기능
- 스트림 키 이름과 값, 필드를 사용할 수 있는 자료구조
💖 캐시 서버로서의 Redis
캐시(cache)는 나중에 요청할 결과를 미리 저장해둔 후 빠르게 서비스 해주는 것을 의미한다. 즉, 미리 결과를 저장하고 나중에 요청이 오면 그 요청에 대해서 DB 또는 API를 참조하지 않고 바로 cache를 접근하여 요청을 처리할 수 있다.
서비스가 커지고 사용자의 요청이 많아 지게 되면 데이터베이스 접근이 늘어나 성능이 떨어질 수 있는데, 이를 캐시 서버를 두어 해결할 수 있다. 동일한 요청에 대해 매번 데이터베이스를 접근하지 않고 인메모리 DB인 Redis에서 데이터를 받아 빠르게 응답할 수 있다.
캐싱 전략
1. Look-Aside (Lazy Loading) : 읽기 전략
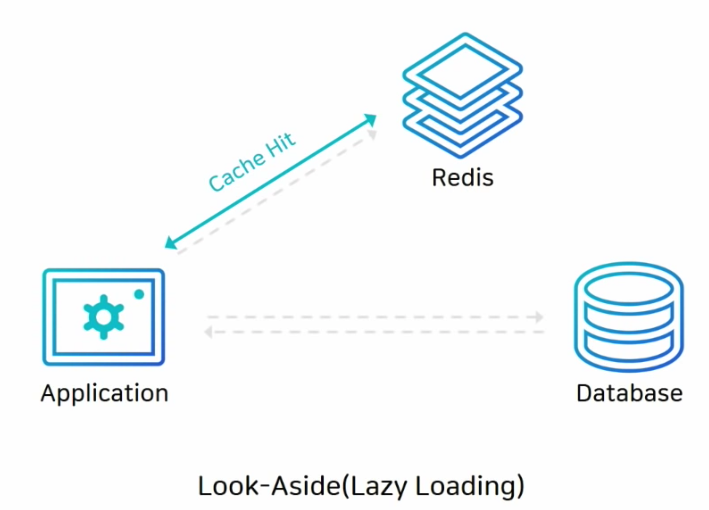
- 캐시에 데이터가 있으면 캐시에 있는 데이터를 가져온다. (cache hit)
- 캐시에 데이터가 없으면 DB에서 데이터를 가져와 캐시에 저장하고 반환한다. (cache miss)
- 캐시 미스가 많으면 DB 커넥션이 많아져 부하가 올 수 있다.
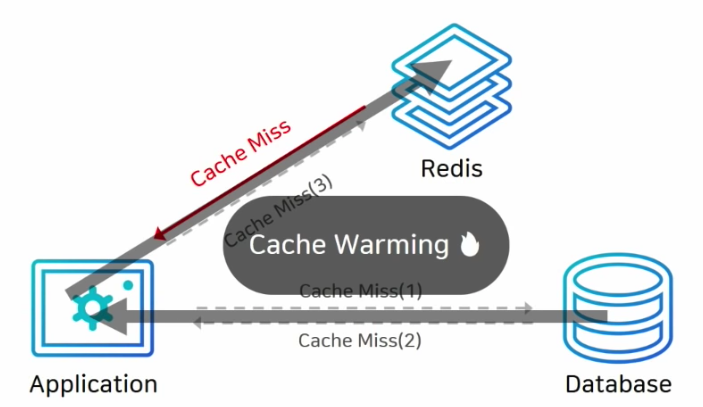
- 초기 데이터를 DB에만 저장했다면 처음에 캐시 미스가 많아 성능 저하 가능성이 있다.
- 미리 DB에서 캐시로 데이터를 넣어주는 작업을 Cache Warming이라고 한다.
2. Read-Through : 읽기 전략
- 캐시에 데이터가 있으면 캐시에 있는 데이터를 가져온다 (cache hit)
- 캐시에 데이터가 없으면 캐시에서 DB에 데이터 조회 요청을 보내 캐시에 저장한다. (cache miss)
- 캐시 서버에 문제가 생기면 전체 서비스의 문제로 이어진다. (캐시에서 DB로 요청하기 때문)
3. Write-Around : 쓰기 전략
- 모든 데이터를 DB에 저장을 하고 캐시 미스일 때 데이터를 캐시에 저장한다. (읽기 시 캐시 미스)
- 캐시 서버와 데이터베이스 간의 일관성을 보장할 수 없다.
4. Write-Through : 쓰기 전략
- DB에 데이터를 저장할 때 캐시에도 데이터를 같이 저장한다.
- 항상 최신 정보를 가지고 있지만 저장할 때마다 2단계 과정을 거쳐 상대적으로 느리다.
- 캐시에 넣은 데이터를 저장만 하고 사용하지 않을 가능성이 있어 리소스 낭비 가능성이 있다.
- 데이터의 expire date를 설정하는 것을 권장
5. Write-Back : 쓰기 전략
- 데이터를 캐시 서버에 먼저 저장해두고 특정 시점마다 DB에 저장한다.
- 캐시 서버 데이터가 DB에 저장되면 캐시 서버에서 삭제된다.
- 쓰기 작업이 많은 경우 많은 쿼리를 한번에 실행할 수 있어 효율적이다.
- 캐시 서버에 문제가 생긴다면 데이터가 손실될 가능성이 있다.
💌 메시지 브로커로서의 Redis
Redis는 메시지 브로커로서 사용이 가능하다. 다양한 메시지 브로커 RabbitMQ, ActiveMQ, Kafka 등 중 Redis는 언제 사용하는 것이 좋을까?
Redis는 인메모리 방식인 만큼 속도 측면에서 좋기 때문에 메시지 브로커로 사용 시에 단기 메시지를 빠르게 처리하는데 적합하다. 하지만 구독자가 존재하지 않는 메시지는 저장하지 않는 특징이 있어 수신확인을 하지 않기 때문에 전송이 보장되지 않음에 유의해야한다.
⚙️ Redis Architecture
[NHN FORWARD 2021] Redis 야무지게 사용하기 를 참고하여 정리한 내용입니다.
Architecture
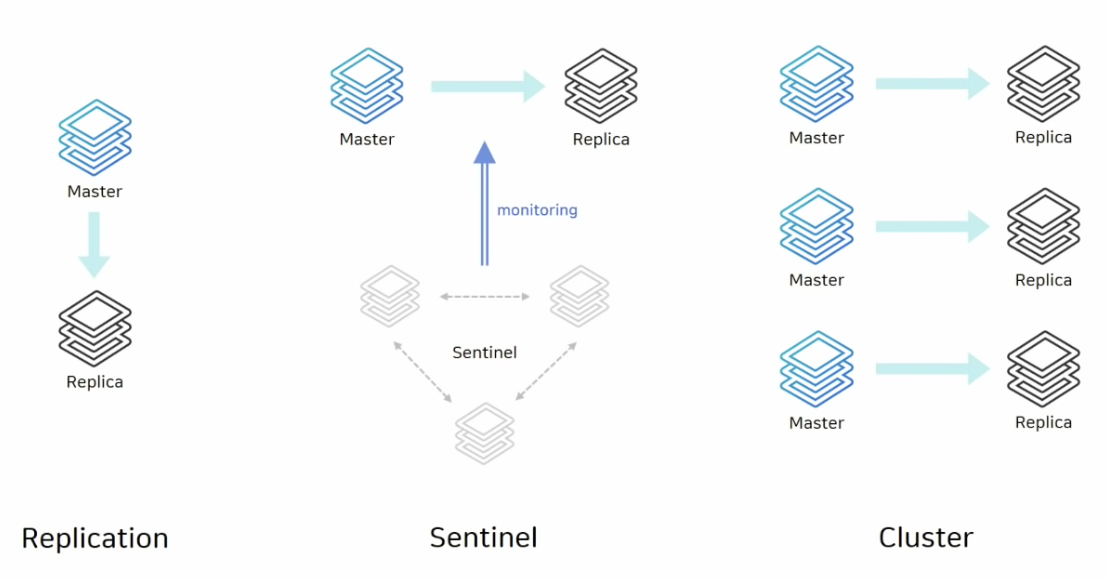
Replication 구성
- master와 replica로 구성
- 단순한 복제 연결 시 사용
- replicaof 커맨드를 이용해 간단하게 복제 연결
- 비동기식 복제
- 복제가 잘됐는지 확인하지 않음
- HA (High Availability) 기능이 없으므로 장애 상황 시 수동으로 복구
- replicaof no one
- 애플리케이션에서 연결 정보 변경
Sentinel 구성
- sentinel, master, replica로 구성
- 자동 Failover 가능한 HA 구성
- sentinel 노드가 다른 노드를 감시(master, replica)
- master가 비정상 상태일 때 자동으로 Failover (자동 복구)
- 연결 정보 변경 필요 없음
- sentinel 노드는 항상 3대 이상의 홀수로 존재해야함
- sentinel 노드도 장애상황이 발생할 수 있기 때문
- 과반수 이상의 sentinel이 동의해야 Failover 진행
Cluster 구성
- 클러스터에 포함된 노드들이 서로 통신하는 구조
- 스케일 아웃과 HA 구성
- 클러스터 내부에는 sentinel과 동일하게 master와 replica가 짝을 이루어 데이터 복제
- 클러스터 내부의 모든 노드는 서로 연결되어 있는 메시(Mesh) 구조이며, 가십 프로토콜(Gossip Protocol)을 사용하여 서로 모니터링
- 가십 프로토콜
- 노드 간의 정보 교환 및 클러스터 상태를 유지하기 위한 프로토콜
- 분산 시스템에서 노드 간의 동적인 상태 정보를 주기적으로 교환하여
- 클러스터의 안정성을 유지하고 동작 상태를 파악하는 데 사용
- 가십 프로토콜
- 키를 여러 노드에 자동으로 분할해서 저장(샤딩)
- 샤딩(Sharding)
- 대용량 데이터를 분산 저장하고 처리하기 위한 데이터 베이스 설계 및 아키텍처 패턴 중 하나
- 데이터베이스는 여러 노드로 나뉘어져 각 노드가 일부 데이터를 처리
- 각 노드를 샤드라고 하며, 각 샤드는 독립적으로 작동할 수 있는 완전한 데이터베이스
- Redis Cluster는 해시함수를 사용하여 어떤 노드에 저장할지 결정(샤딩키)
- 각 노드는 해시 함수를 통해 특정 범위의 해시슬롯에 매핑됨
- 샤딩(Sharding)
- 모든 노드가 서로를 감시하여, master가 비정상 상태일 때 자동으로 Failover
- 최소 3대의 master 노드가 필요
아키텍처 선택 기준
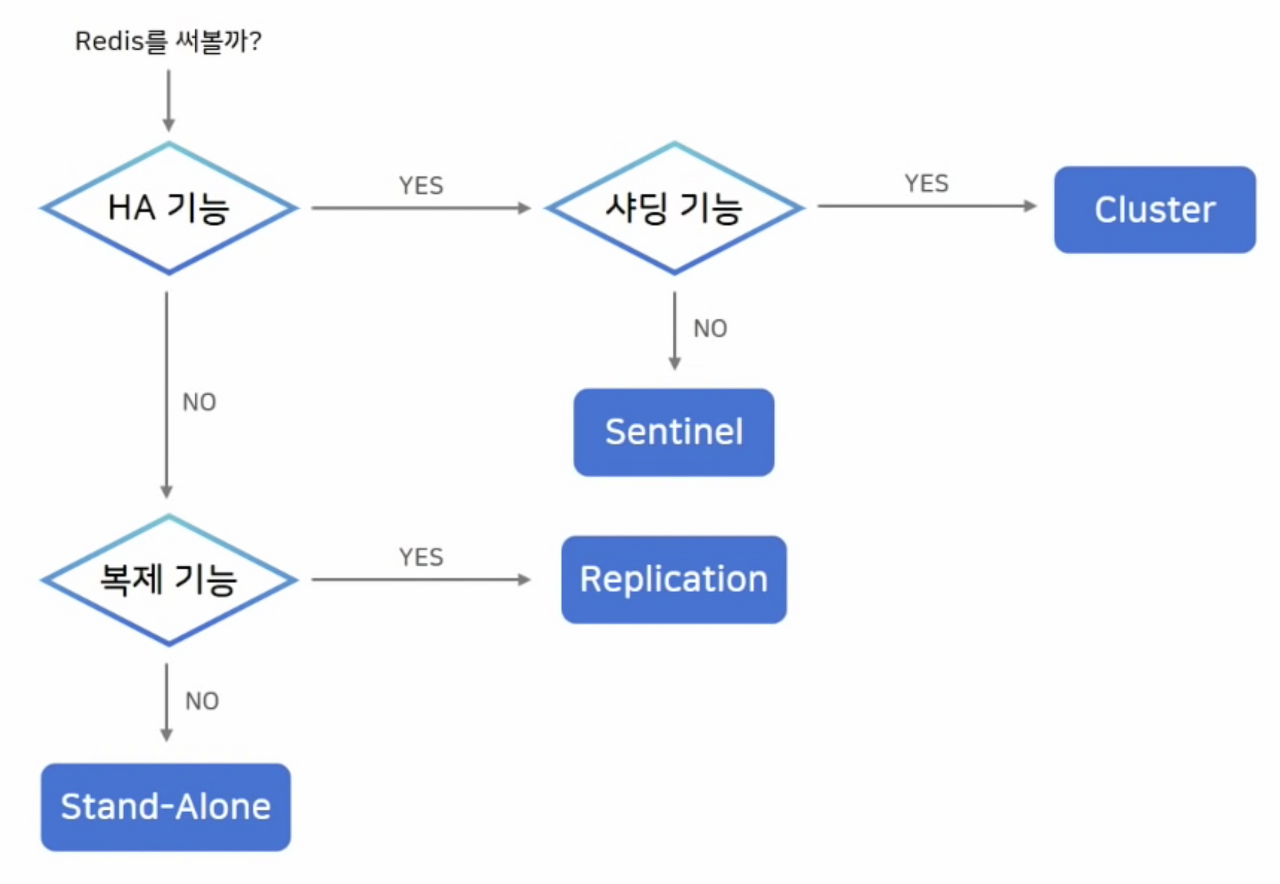
👍🏻 Redis 사용
Redis는 언제 사용하는 것이 효과적일까?
- 보조 데이터 저장소
- 영속성을 통해 주 데이터 저장소로 사용 가능하지만 In-Memory 방식으로 메모리 제한 존재
- 주 데이터 저장소 보다는 보조 데이터 저장소로 사용할 것
- 데이터 캐시
- 인메모리 데이터 저장소로서 데이터를 캐시하여 사용 가능
- 공유자원 저장
- 여러 시스템이 동시에 사용하는 데이터에 대해 저장하기
- 싱글스레드이기 때문에 데드락을 방지할 수 있음
- 순위 계산
- Sorted Set 자료구조를 이용해 순위 계산 용도로 사용할 수 있음
참고 :
728x90'Computer Science > Database' 카테고리의 다른 글
[Kafka] 아파치 카프카(Apache Kafka)에 대해서 (1) 2023.12.20 [메시지 큐] 메시지 큐에 대해서 (메시지 큐, MOM, 특징, 이점 등) (0) 2023.12.10 [SQL] 집계 함수를 쓰기 어려울 때 over()와 서브 쿼리 중 뭐를 사용해야 할까? (0) 2023.10.13 [SQL] JOIN 정리 (0) 2022.07.14 [SQL] DML (0) 2022.07.14